
伪共享
CPU基本架构了解
伪共享本质是cpu的缓存问题,那么首先先介绍cpu的读写问题。
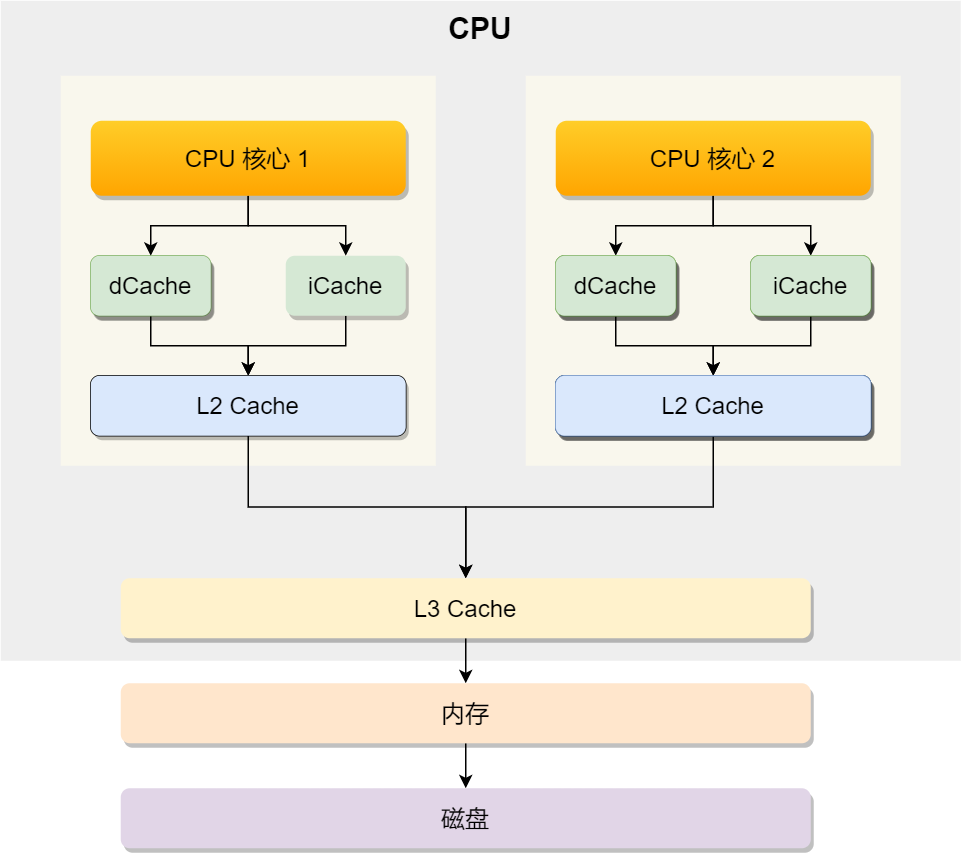
首先是cpu的架构。cpu一般不止一个核心,有多个核心,其中如上图,每个核心自己会有两个缓存区,即L1 Cache(由指令缓存区(iCache)和数据缓存区(dCache)组成),L2 Cache这两个缓存区间,其中所有核心还有个共享缓存区间,即L3 Cache。以上就是cpu的典型架构。
共享缓存中的内容遵循MESI协议。MESI 协议是指一种缓存一致性协议,用于确保多核处理器系统中各个核心的缓存数据与内存数据保持一致。其通过跟踪每个缓存行的状态来管理数据的一致性,这四个状态的首字母分别代表:Modified、Exclusive、Shared 和 Invalid。这个协议允许处理器核心之间进行有效的数据同步,从而避免数据不一致的问题。
其中L1和L2的随机访问延时分别是1ns和4ns。这里缓存器主要作用是将数据提前写入缓存层,减少对内存的频繁访问量和节省时间。当cpu从内存读取数据时并非是将数据挨个按照字节读取,而是一次性写入一整块内存内容,这一整块内容我们称之为Cache Line(缓存行),即Cache Line是cpu从内存读取数据到Cache的单位。其中对数组的加载,CPU会加载连续多个数据到Cache,那么在我们访问元素时使用物理内存分布顺序去访问,就会大大提高Cache的命中率,能减少从内存读取的频率提高程序性能。
什么是伪共享,伪共享是怎么形成的
上面我们说过,在同一个 Cache Line 中遵循缓存一致性原则,那么伪共享就是在这个过程中Cache Line中同时包含了核心1和核心2分别要使用的数据的物理地址,那么此时在代码中虽然是多线程进行,但是其实没有进行真正的分开同步操作。具体场景流程如下:
- 有两个变量a、b在同一个缓存行中
- 两个线程:
- 线程1:绑定在cpu核心1,只对a进行写操作
- 线程2:绑定在cpu核心2,只对b进行读操作
- 初始状态:还未被任何核心读取
此时在以上背景下可能出现已下事件:
- 线程2读取了b,那么缓存行载入核心2的缓存,此时核心2的缓存标记为shared,此时数据未作任何修改是与L3 Cache中的内容是一样的。
- 线程1读取了a,加载了该缓存行,此时核心1的状态为shared,同时这时也未做任何的数据修改,数据与共享缓存中的数据是一致的。
- 线程1准备开始修改数据a,此时状态再次更改为Exclusive,拿到这块内存的唯一主导权。
- 线程1修改数据a,此时状态更改为Modified,核心2中的数据状态更改为Invalid,此时因为核心2要读取数据b内容,由于缓存行数据不一致根据缓存一致性原则就导致核心2要重新载入缓存行,那么此时重新更新状态为shared。
根据以上情景可以得知在多线程中如果多个资源之间正好放到了同一个缓存行中,那么在cpu处理时就会跳入主导权的反复更迭以及数据的重复加载,这就是伪共享的形成方式
解决伪共享的方法
- 使用alignas
1 | struct alignas(64) ThreadData{ |
- 手动填充
1 | struct PaddedCounter{ |
- 使用 std::hardware_destructive_interference_size 来获取Cache Line的大小(c++ 17)
1 |
|
- c++17以及以上使用new自动对齐
1 | struct alignas(64) MyData{int x;} |
- 使用thread_local避免共享,让每个线程拥有独立的副本从根本上杜绝共享
1 | thread_local int local_counter =0; |
- 调整数据访问模式
1 | //对于数组,缓存行大小跳步,避免线程之间踩到同一行 |



