
cpp网络编程基础(三)
三次握手和4次挥手
一. 三次握手
tcp是可靠的连接,在tcp连接时需要进行3次对话(握手)
在服务端进行监听时listen客户端就可以向服务端发送请求connect进行连接,这是首次进行对话,在这个过程中,当客户端调用connect时就会触发三次握手。
当三次握手完成后,客户端和服务端就会建立起一个双向的传输通道。
具体图示如下:
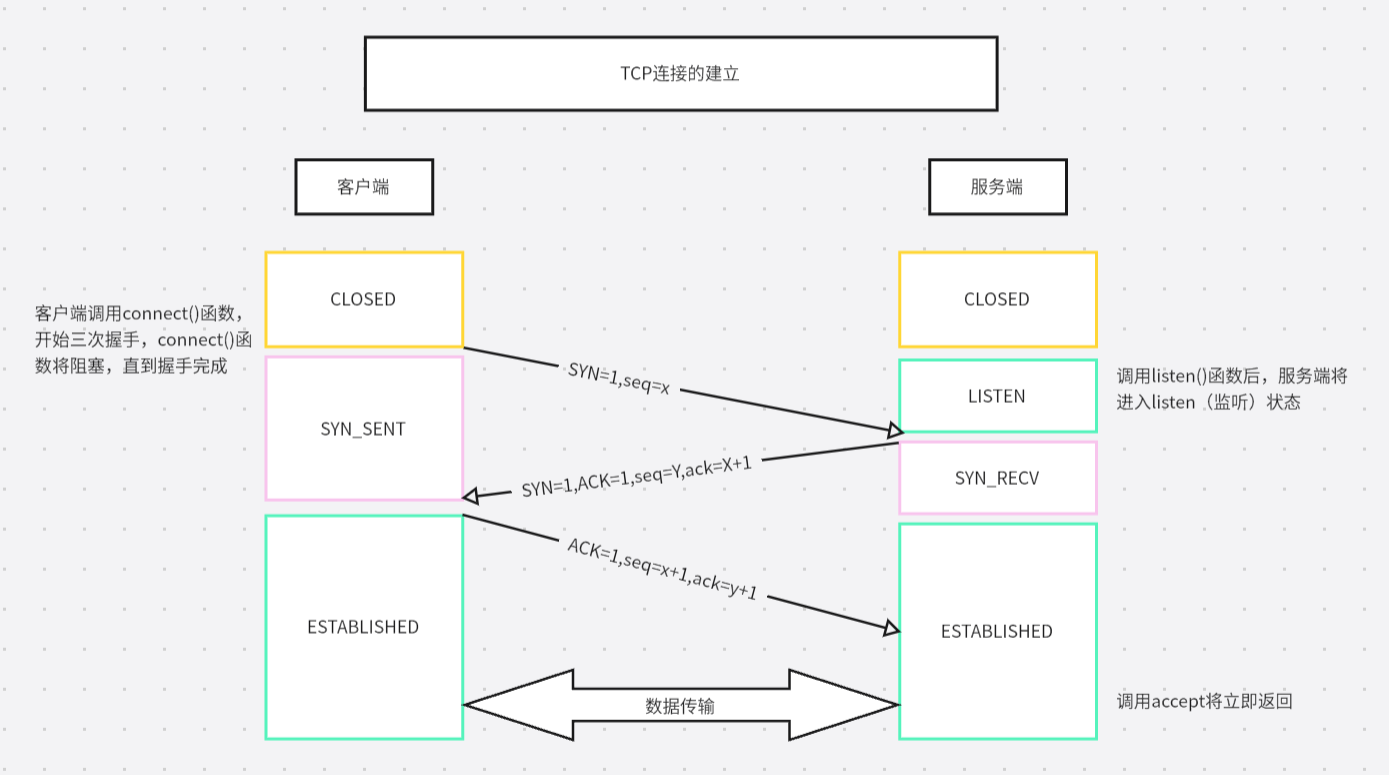
注意:
-
客户端的socket也有端口号,但是不需要关心,所以客户端的socket是随机分配的。
-
服务端的
bind()函数,普通用户权限只能使用1024端口以上的端口,而root权限用户则可以使用所有端口。 -
listen()函数的第二个参数+1为已连接的队列(ESTABLISHED状态)的大小。超过这个数量的客户端连接到同一个socket进程后的状态会显示为SYN_RECV状态,也称之为半连接状态。 -
上方的图中的状态
CLOSED状态是不存在的假想状态。
二. 四次挥手
断开一个TCP连接时,客户端和服务端需要相互总共发送四个包以确认连接的断开。在socket编程中,这一过程由客户端或服务端任意一方执行close()触发
具体流程图如下:
注意:
-
主动断开端在四次挥手后,socket的状态为
TIME_WAIT,该状态将持续2MSL(30s/1min/2min)。MSL(Maximum Segment Lifetime)报文在网络上存在的最长时间,超过这个时间报文将被废弃。 -
如果是客户端主动断开,
TIME_WAIT的状态几乎不会造成危害,原因如下:- 客户端程序的socket程序很少。
- 客户端的端口是随机分配的,不存在重用的问题。
-
如果是服务端主动断开,有两方面危害:
- socket没有立即释放。
- 端口号只能在2MSL后才能继续使用。
在服务端程序中,用
setsockopt()函数设置socket属性(一定要放在bind()之前)1
2
3
4
5
6int opt = 1;
setsockopt(m_listenfid,
SOL_SOCKET,
SO_REUSERADDR,
&opt,
sizeof(opt));
socket函数有关参数解释
在cpp中我们的网络组件都是由以下几个关键接口组成:
服务端:
-
socket:网络通信对象 -
bind:绑定IP和端口,作为通信入口 -
listen:开启监听,等待客户端请求 -
accept:接收客户端连接请求 -
send:发送数据 -
recv:接收数据 -
close:关闭连接
客户端:
socket:网络通信对象connect:连接服务器send:发送数据recv:接收数据close:关闭连接
一. socket函数参数
socket创建:
1 | int socket(int domain,int type,int protocol); //Linux |
创建成功返回一个有效的socket,失败返回-1,errno被设置。
参数不错的情况下基本不会失败。
单个进程中创建的socket数量与受系统参数open files的限制(socket本质也是文件描述符)
-
domain家族:AF_INET:IPv4互联网协议族AF_INT6:IPv6互联网协议族AF_LOCAL:本地通信协议族AF_PACKET:内核底层协议族AF_IPX:IPX Novell协议族
-
type数据传输类型:SOCK_STREAM面向连接的socket:- 数据不会丢失
- 数据顺序不会错乱
- 双向通道
SOCK_DGRAM无连接的socket:- 数据可能会丢失
- 数据顺序可能会错乱
- 传输效率更高
-
protocol最终使用协议:
IPv4网络家族协议中,数据传输方式为SOCK_STREAM的协议只有IPPROTO_TCP,数据传输方式为SOCK_DGRAM协议的只有IPPROTO_UDP。
此处参数也可以填0编译器可自动识别
TCP和UDP
1 | socket(PF_INET,SOCK_STREAM,IPPROTO_TCP); |
二. bind函数参数
1 | int bind(int sockfd,const struct sockaddr *addr,socklen_t addrlen);//Linux |
给socket绑定一个地址,这样client对这个地址收发相应的数据就能和socket关联如果绑定失败会返回-1,erron被设置
在服务端中必须要进行调用,在客户端中不需要调用,也可以调用,如果不调用则由系统自动绑定本机地址和随机分配端口进行连接
sockfd:socket文件描述符addr:构建sockaddr的结构体包含IP端口等信息addrlen:结构体addr的参数长度
三. listen函数参数
1 | int listen(int sockfd,int backlog);//Linux |
当服务器开启监听后会等待客户端的连接请求,如果开启失败会返回-1,erron被设置
同样在服务器中必须要被调用以用来接收请求
sockfd:socket文件描述符backlog:指定了服务器排队的最大连接数,当客户端发起请求时,服务器需要时间来处理请求,因此会有一个队列来存储这些暂时不能处理的请求。如果并发量小一般可以设置为10-20。如果将其设置为SOMAXCONN则是由系统来决定请求队列长度,这个值一般比较大,可能是几百甚至更多。当队列满后不再接收新的请求。
四. accept函数参数
1 | int accept(int sock,struct sockaddr* addr,socklen_t *addrlen);//Linux |
accpet是专门用来接收客户端请求用的,与listen配套使用
sock:服务器套接字(这里是服务器的而不是客户端的)addr:保存的是客户端的相关信息。后续要使用addr进行与客户端的通讯addrlen:结构体的大小。
跟listen进行区分,在listen只是开启了监听,而accept才是真正进行接收工作。accept会阻塞程序运行,直到由新的请求
五. send/recv函数参数
1 | //Linux |
send和recv都是用来对字节流的传输和接收,其中Linux中还有read()和write()的使用如下:
1 | //仅限Linux |
两者明显的区别是write和read没有flag参数,然而在使用时基本使用send和recv因为功能更全面且两个平台均支持,所以兼容性也更好。
-
sockfd:目标端套接字 -
sendbuffer:要发送的消息(win端要转化为字符数组类型地址,Linux可以直接发送结构体) -
recvbuffer:要发送的消息(win端要转化为字符数组类型地址,Linux可以直接发送结构体) -
nbytes:要发送消息的字节长度
六. close函数
1 | close(int sockfd);//Linux |
用来关闭连接使用,关闭自身socket对象。
TCP缓存
系统为每个socket创建了发送缓冲区和接收缓冲区,应用程序调用
send()或者write()函数发送数据的时候,内核吧数据从应用进程拷贝socket的发送缓冲区中;应用程序调用recv()或者read()函数接收数据的时候,内核把数据从socket的接收缓冲区拷贝进应用进程中。
发送数据即把数据放入发送缓存区。
接收数据即从接收缓冲区中取数据。
查看socket缓存大小:
1 | int bufsize = 0; |
注意:
send():函数在发送缓存区或者对端的接收缓存区满了时会阻塞。
- Nagle算法
在TCP协议中无论发送多少数据,都要在数据前面加上协议头,同时对方接收到数据后也要回复ACK表示确认,为了尽可能的利用网络带宽,TCP每次希望都能够以MSS(Maximum Segment Size,最大报文长度),的数据块来发送数据。
Nagle 算法就是为了尽可能发送大块数据,避免网络中充斥着小数据块
Nagle 算法的定义是:任意时刻,最多只有一个违背确认的小段,小段是指小于MSS的数据块,违背确认是指一个数据块发送出去后,没有收到对端回复的ACK。
- ACK延迟机制
TCP协议中不仅仅有Nagle算法,还有一个ACK延迟机制:
当接收端收到数据后,并不会马上向发送端回复ACK,而是延迟40ms后再回复,它希望再40ms内接收端会向发送端回复应答数据,这养ACK可以和应答数据一起发送,把ACK稍带过去。
如果TCP连接的一段启用了Nagle算法,另一端启用了ACK延迟机制,而发送的数据包又比较小,则可能出现这样的情况:发送端在等待上一个包的ACK,而接收端正好延迟了此ACK,那么这个正要发送的包就被延迟了40ms。
解决方案
开启TCP_NODELAY,开启后就是禁用Nagle算法
1 |
|
对时效要求高的系统中,如联机游戏就会禁用Nagle算法。



